Building distributed systems is challenging. If not carefully designed and implemented, a failure in one component can cause cascading failures that affect the whole system. That's why patterns like Retry and Circuit Breaker should be considered to improve system resilience. In case of sending WebHooks the situation might be even worse as your system is calling a totally external system with no availability guarantees and over the internet which is less reliable than your internal network.
Continuing on the previous parts of this series (Part 1, Part 2) I'll show how to use Azure Event Grid to overcome this challenge.
As per the documentation failed requests will be retried after 10 seconds, and if the request fails again, it will keep retrying after 30 seconds, 1 minute, 5 minutes, 10 minutes, 30 minutes, and 1 hour. However these numbers aren't exact intervals as Azure Event Grid adds some randomization to these intervals.
Events that take more than 2 hours to be delivered will be expired. This duration should be increased to 24 hours after the preview phase.
This behavior is not trivial to implement which adds to the reasons why using a service like Azure Event Grid should be considered as an alternative to implementing it's capabilities from scratch.
Continuing on the previous parts of this series (Part 1, Part 2) I'll show how to use Azure Event Grid to overcome this challenge.
Azure Event Grid Retry Policy
Azure Event Grid provides a built-in capability to retry failed requests with exponential backoff, which means that in case the WebHook request fails, it will be retried with increased delays.As per the documentation failed requests will be retried after 10 seconds, and if the request fails again, it will keep retrying after 30 seconds, 1 minute, 5 minutes, 10 minutes, 30 minutes, and 1 hour. However these numbers aren't exact intervals as Azure Event Grid adds some randomization to these intervals.
Events that take more than 2 hours to be delivered will be expired. This duration should be increased to 24 hours after the preview phase.
This behavior is not trivial to implement which adds to the reasons why using a service like Azure Event Grid should be considered as an alternative to implementing it's capabilities from scratch.
Testing Azure Event Grid Retry
To try this capability and building on the example used in Part 1, I made a change to the AWS Lambda function that receives the WebHook to introduce random failures:public object Handle(Event[] request)
{
Event data = request[0];
if(data.Data.validationCode!=null)
{
return new {validationResponse = data.Data.validationCode};
}
var random = new Random(Guid.NewGuid().GetHashCode());
var value = random.Next(1 ,11);
if(value > 5)
{
throw new Exception("Failure!");
}
return "";
}
Lines 9-15 produce almost 50% failure rate. When I pushed an event (as shown in the previous posts) to a 1000 WebHook subscribers, the result was the below chart depicting the number of API calls per minute and number of 500 errors per minute:
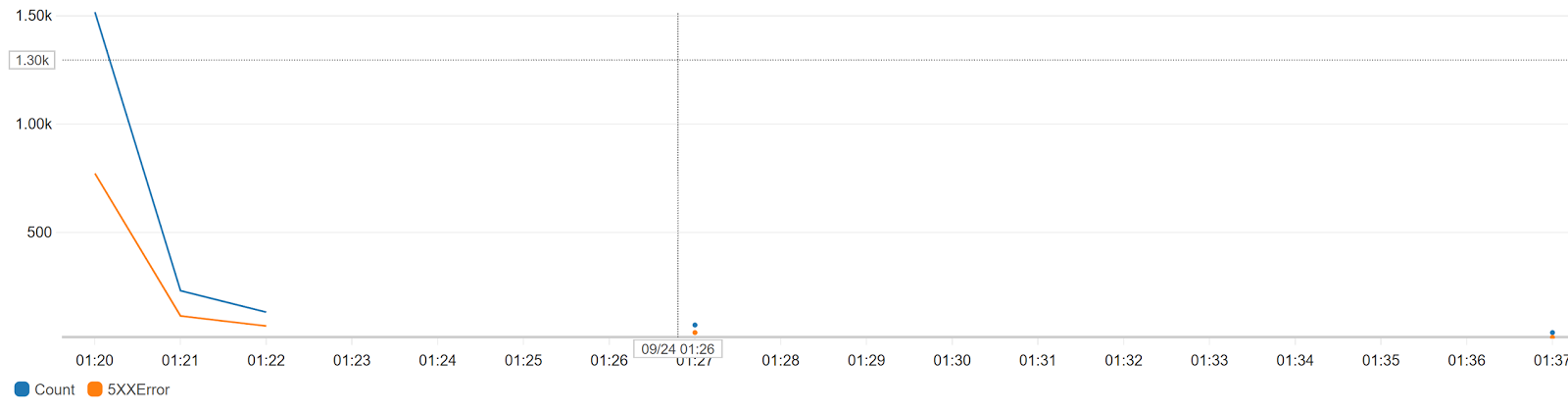 |
| Number of requests per minute (Blue) - Number of 500 Errors per minute (Orange) |
We can observe the following:
- The number of errors (orange) is almost half the number of requests (blue)
- Number of requests per minute is around 1500 for the first minute. My explanation is that since we have 1000 listeners and 50% failure rate, Azure has made extra 500 requests.
- After a bit less than 2 hours (not shown in the chart for size constraints) the number of errors has dropped to 5 and no more requests were made. This is due to the expiration period during the preview.
Summary
Azure Event Grid is a scalable and resilient service that can be used in case of handling thousands (maybe more) of WebHook receivers. Whether your solution is hosted on premises or on Azure, you can use this service to offload a lot of work and effort.I wish that Azure Event Grid could give some insights on how events are pushed and received which would help a lot in troubleshooting as the subscriber is usually not under your control. I hope this will become an integrated part of the Azure portal.
It's worth mentioning that other cloud providers support similar functionality as Event Grid that are worth checking, specifically Amazon Simple Notification Service (SNS) and Google Cloud Pub/Sub. Both have overlapping functionality with Azure Event Grid.




